We have all witnessed the apocalyptic scenes Hollywood portrays in the many movies it produces about the end of the world. One man is usually holding up a sign that reads, “The end is near!” Another character is delivering a sidewalk sermon about the wrath of God. “Jesus is coming!” he exclaims as foreboding weather descends on the crowds of people scattering about in preparation for the impending disaster.
Even if the world seems this way to you, we all have a job to do. Composure is key. We all know it. We have all spent our lives coping with our own personal circumstances. They may not add up to the end of society as we know it, but we still feel an impact from the obstacles we face as we journey through life.
It sure would make it easier for all of us if the networks upon which we depend maintained a dependable level of stability. After all, as one of my very first mentors instructed me, “Networks are like grammar. You only notice them when they are bad.”
By now, the Crowdstrike incident has come and gone. While the world is still standing, and the sun has come up every day since, there are plenty of lessons to be gleaned from the whole debacle. It seems implausible that a single point of failure, one lone update sent from a managed service provider (MSP) could have been so devastating. While we can debate whether we are getting the straight scoop on the root cause, we must recognize that these entities are engaged in a system of systems. Sometimes, a simple mistake brings one system down, and a whole house of cards tumbles down with it. In this case, vast numbers of resources failed, some of them mission critical.
Horrifyingly, the objective was to harden systems against exactly the result it produced. With that in mind, I thought I might take advantage of this teachable moment to revisit the basics of software updates. I think we can all agree that the discussion is warranted.

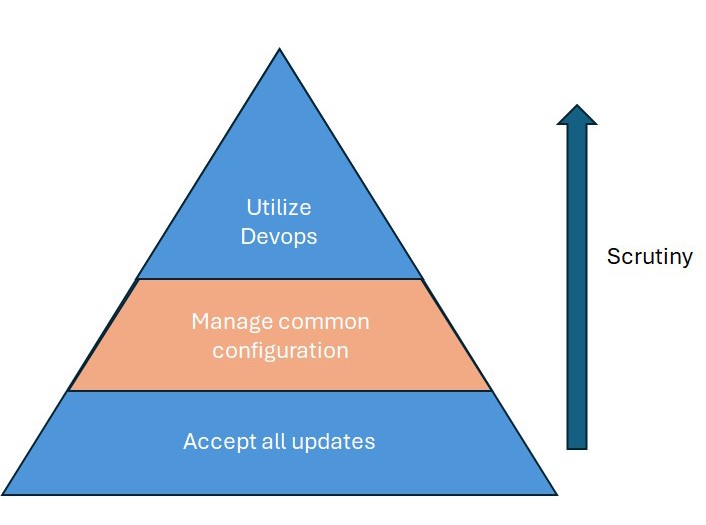
Some time ago, cybersecurity specialists came to a consensus about best practices with regard to software updates. While the discussion essentially began with the notion that we should simply accept the updates that vendors provide, it became apparent to administrators that certain of those updates may fix one problem at the expense of another.
Knowing that the site in question was dependent on a certain service pack, I loaded the patch, and she was able to access the portal. However, days later, that user would complain that she had since lost access to another portal, that required the update to be deprecated. Issues like this led our leadership to understand the importance of a common operating system environment, which has come to be known as a “gold disk.”
The gold disk forced the standardization of the desktop beyond a single platform (eg, simply Windows 11). To achieve consistent access within the user population, operating systems would maintain a common configuration. At that moment, a new role within the organization was realized: configuration management. Leadership within this specialty would work with testers to ensure the latest configurations they authorize do not disrupt operations.
To achieve this testing, labs were developed to mimic operations. In many cases, those labs have developed into full-fledged cloud environments known as DevOps, where proposed configurations are released into the testbed to measure the effect of potential changes. Many DevOps environments have evolved to accommodate a matrix of configuration managers, developers, software testers, and operations personnel who laisse with the others to ensure users’ interests are protected.
This last part is crucial. Operations people know their users. Day in and day out, they are right there in the trenches with their customers. The success of configuration management is so much more probable when those administrators, those operations personnel, are involved in the process. After all, they will be the ones expected to clean up any carnage. This is the ideal within enterprise environments.
In the case of Crowdstrke, however, we are talking about an array of enterprise environments. Given the differences from one organization to another, we may not be able to depend on a well-developed “Gold Disk.” Can we really confirm that anyone is tracking end user configurations? In this case, the targeted user population was so diverse that any update could well have resulted in at least a partial outage.
This is the challenge for organizations like Crowdstrike who essentially provide services to a set of users over which it has no control. Let’s not discount that there are plenty of other companies who provide the same services. In these cases, one might argue a much more formal level of testing is required to ensure the integrity of the user experience.
Crowdstrike has a steep hill to climb. Customers of the managed service provider (MSP) trusted it to assume the responsibility of establishing the enterprise requirements described above. These users were not kids who couldn’t get to YouTube for an hour or two. The operations of hospitals and emergency responders upon whom we depend to preserve lives were disrupted. Customers who require the assistance of billion-dollar institutions were denied service.
Did Crowdstrike not sufficiently test their patches? Was this change approved? By whom? Did any factors mitigate just how pervasive this disruption was to its customer base? Crowdstrike has a lot of questions to consider.
Further, should billion-dollar institutions and mission critical systems be relying on a third party to manage processes so integral to the success of their organizations? For us to maintain composure in the face of all our challenges, every involved party needs to reflect on these circumstances..
If your organization is considering a MSP to maintain your information technology environment, it is highly recommended that you start with the service level agreement (SLA) which defines what your leadership deems acceptable for the maintenance and stability of your systems. Once we understand how that stability affects our mission, we can make better decisions about how to best preserve our resources.
